 Sebin
SebinIf you've ever scratched your head wondering how Git, the go-to tool for version control, manages to keep each commit as unique as a snowflake, you're in for a treat. Today, we're pulling back the curtain to reveal the wizardry behind Git - and it's all about Merkle Trees and the nifty process of hashing.
Hashing
First off, what exactly is a hash? Imagine taking a bunch of data and squishing it into a fixed-length string of characters - that's hashing in a nutshell. It's like a culinary recipe that always gives you the same cake, no matter how many times you bake it, as long as you follow the recipe to the end. And the beauty of it? It's a one-way street – you can't un-bake the cake to get the original ingredients. The popular hashing algorithms include MD5, SHA, RIPEMD-160 as so on.

Merkle Tree
Merkle tree or hash tree was first conceptualized by Ralph Merkle an American computer scientist and mathematician in 1979. A merkle tree is a tree of hashes which is built from bottom up where the leaf node (a child node with no further children) are represented as a hash of data blocks. The parent of the leaf nodes are represented as a hash of concatenation (joining a string from end-to-end) of the hash of its child nodes. Now this step is continued till we get a single node or a root node.
In the first illustration, the root node represents the initial state of the folder, with the hash of each file in the folder used to build the tree. In the second illustration, we can see that the root node has changed, indicating that at least one file in the folder has been modified. This change in the root node causes the entire tree to change, as the parent nodes must also be updated to reflect the new hashes of their child nodes.
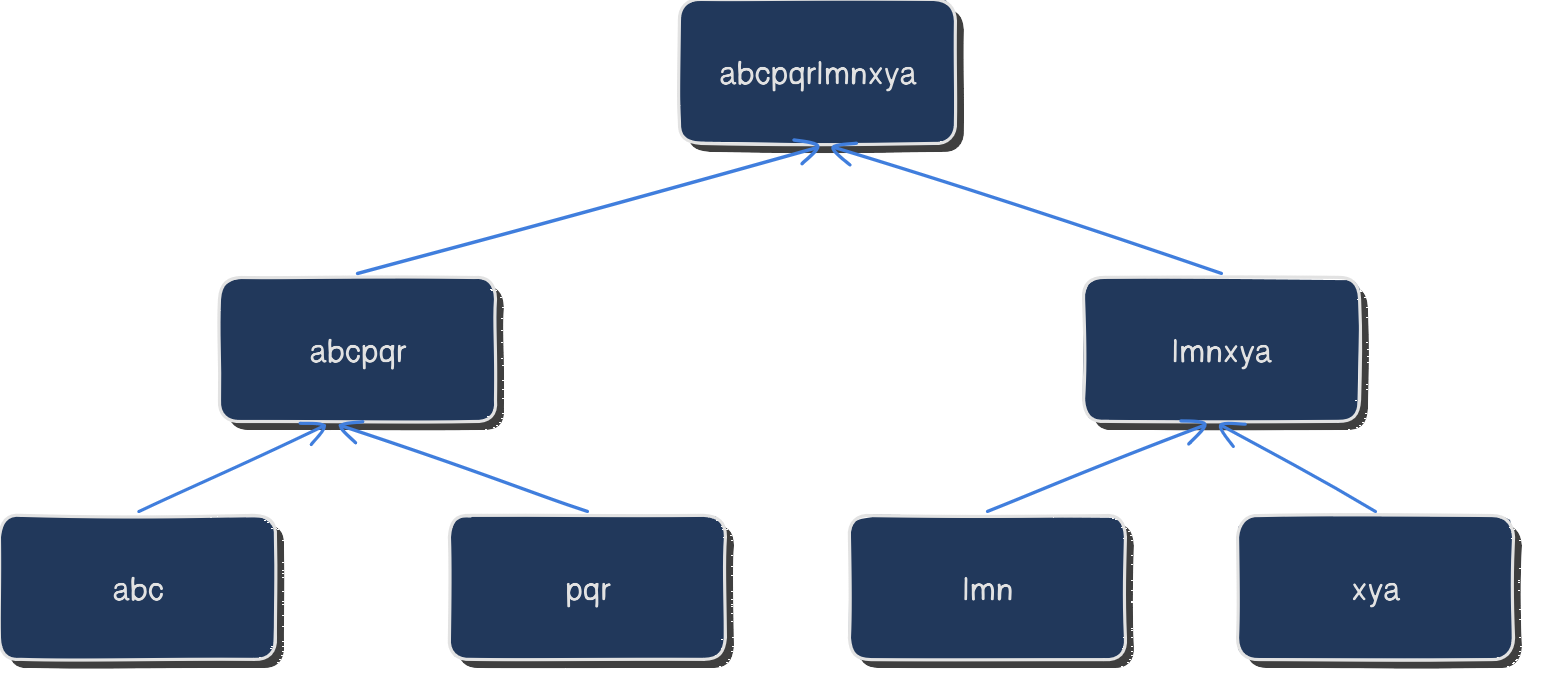
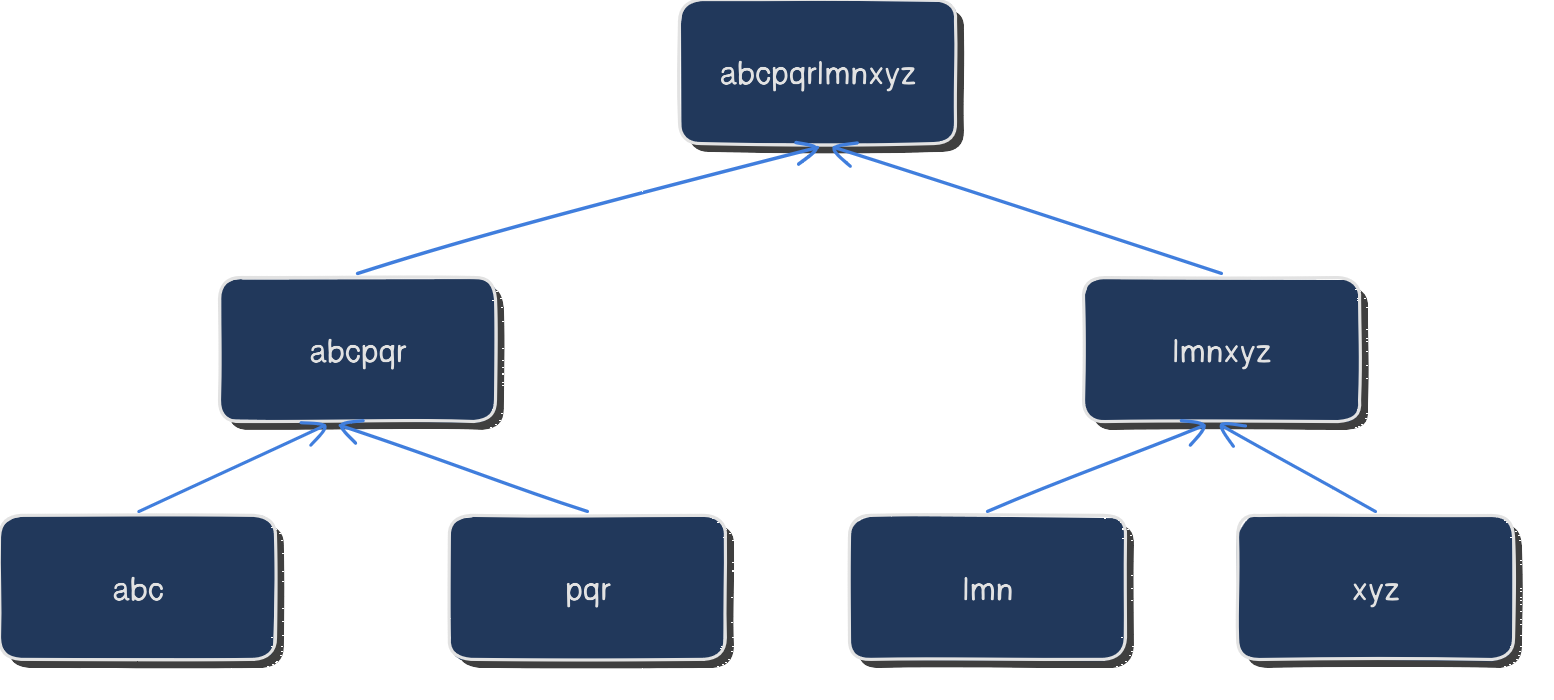
Git uses Merkle trees to efficiently track changes to files in a repository. Each file in Git is represented as a leaf node in a Merkle tree, with the SHA-1 hash of the file's contents used as the node's value. The hash is computed based on the file's contents, as well as the file's name and any relevant metadata, such as the file permissions.
When a file is modified, even slightly, the SHA-1 hash of the file will change, which in turn will cause the hashes of the parent nodes in the Merkle tree to change. This allows Git to quickly and efficiently identify which files have been modified, added, or deleted in a repository.
In addition to tracking changes to individual files, Git also uses Merkle trees to track changes to entire directories and even the entire repository. This is done by creating a separate Merkle tree for each directory and subdirectory in the repository, with the root node of each tree representing the contents of that directory. The root nodes of these trees are then combined into a higher-level Merkle tree, which represents the entire repository.
By using Merkle trees in this way, Git is able to efficiently track changes to large repositories with thousands or even millions of files. When a developer makes a change to a file, Git can quickly and efficiently identify the changes and update the Merkle tree accordingly.
For extended reading:
Connect with Me
Email: sebinsebzz2002@gmail.com
GitHub: github.com/sebzz2k2